2019
Calculating Pi: Alerting on changes to y-cruncher Checkpoint File
This is a continuation of my Pi world record attempt series. Before I quit y-cruncher and start a backup, I need to know when the y-cruncher checkpoint file is modified. To accomplish this task, I use a program called incron1. incron is able to detect file/directory changes and run commands as a result. In my case, I have a bash script that is executed when the y-cruncher Checkpoint File is modified, which will send me a text message (using Twilio API). Below is a copy of my incron configuration and the script which send a text message. The script isn’t perfect, but it works well enough for me.
$ incrontab -l
/home/tim/y-cruncher\ v0.7.7.9500-dynamic IN_CREATE,IN_DELETE /home/tim/send_text.sh $# $%
#!/bin/bash
# This script is executed by incron to send a text message (using Twilio) upon modification of the y-cruncher Checkpoint file. There is logic to only alert once for a single file change, so duplicate texts will not be sent.
#################################
# Copyright 2019 Timothy Mullican
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#################################
#!/bin/bash
account_sid="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
auth_token="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
state_file=~/files_already_alerted.txt
if [ -z "$1" ]; then
output="New checkpoint file created."
else
output="incron (y-cruncher): $@"
filepath="/home/tim/y-cruncher v0.7.7.9500-dynamic/$1"
if [[ -f "$filepath" ]]; then
last_line=$(tail -n 1 "$filepath")
# remove any special formatting or unprintable characters
last_line=${last_line%$'\r'}
output="$output (last line: $last_line)"
fi
[ ! -f $state_file ] && touch $state_file
if grep "$1 $last_line" $state_file; then
echo "Previously alerted on file. Exiting..."
exit 0
else
echo "$1 $last_line" >> $state_file
fi
fi
echo "$output"
from_number="+XXXXXXXXXX"
to_number="+XXXXXXXXXX"
echo "From: $from_number"
echo "To: $to_number"
curl -s -X POST -d "Body=$output" \
-d "From=$from_number" -d "To=$to_number" \
"https://api.twilio.com/2010-04-01/Accounts/$account_sid/Messages" \
-u "$account_sid:$auth_token"
-
https://www.howtoforge.com/tutorial/trigger-commands-on-file-or-directory-changes-with-incron/ ⤴
Calculating Pi: Remove unneeded y-cruncher files before a backup
This is a continuation of my Pi world record attempt series. Below is the script I use to remove unneeded files from drives when generating a y-cruncher backup. It’s quick and dirty, but does the job. If you neglect to remove unneeded files in between y-cruncher runs, you risk the disk running out of space and your computation failing. Anyways, I run this script right before executing the Veeam backup to tape job.
#!/bin/bash
# This script analyzes a y-cruncher checkpoint file to remove any unneeded files in preparation for a backup to be run. y-cruncher MUST be stopped before running this in order to avoid potential data loss.
#################################
# Copyright 2019 Timothy Mullican
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#################################
checkpoint_file="$1"
declare -a files
files=()
num_drives=48
# From https://stackoverflow.com/a/14367368
array_contains2 () {
local array="$1[@]"
local seeking=$2
local in=1
for element in "${!array}"; do
if [[ $element == $seeking ]]; then
in=0
break
fi
done
return $in
}
if [ -z "$1" ]; then
echo "y-cruncher Checkpoint file not specified!"
exit 1
fi
if [ ! -f "$1" ]; then
echo "File \`$1\' does not exist!"
exit 1
fi
while read -r line; do
f=$(echo "$line" | sed 's/Object\:[ \t]*//g')
# remove any lingering non-printable characters
f=${f%$'\r'}
f=$(echo "$f" | sed $'s/[^[:print:]\t]//g')
files+=($f)
done <<<$(grep Object "$checkpoint_file")
i=1
# loop over all the drives. In my case, the drives used during the computation started at /drives/1 and ended at /drives/48, but y-cruncher starts at zero, so we need to subtract the drive minus 1. An example: /drives/1/ycs-00-0 and /drives/9/ycs-08-0/.
while [ $i -le $num_drives ]; do
# prepend 0 if drive 9 or less
if [ $i -le 10 ]; then
drive_path=/drives/$i/ycs-0$((i - 1))-0/*
else
drive_path=/drives/$i/ycs-$((i - 1))-0/*
fi
for file in $drive_path; do
if array_contains2 files $(basename "$file"); then
continue
else
echo "[drive#$i] Unneeded file: $file"
rm -rf "$file"
fi
done
# increment counter
i=$[$i+1]
done
Calculating Pi: Hard Drive Backups
This is a continuation of my Pi world record attempt series. This blog post will talk about how I handle backups during the world record attempt. Due to the vast amount of computation storage required, implementing RAID or other types of redundant storage were not feasible. To mitigate the risk of drive failure, I decided to purchase a tape library and drive. Tape is typically more stable than hard drives when stored under appropriate conditions, since there is no spinning media. One thing I was warned about is that y-cruncher will leave behind files on drives used during the computation. Not all of these files are required to be backed up, and the unneeded ones should be removed before starting a backup.
First, before starting a backup, I stop the y-cruncher program. This is to ensure the y-cruncher checkpoint file and files on disk are not overwritten. Next, since there wasn’t an existing way to automatically remove the unneeded files from the hard drives, I wrote a simple Bash script to delete files that are not required by the y-cruncher checkpoint file. After I have deleted the unneeded files from the drives, I have an ansible script which connects to the Dell R720xd running Windows Server 2016. The script executes a Veeam direct file-to-tape backup job on the fly. The script is also able to provide an estimated completion time, since Veeam doesn’t provide a time estimate natively. I will make these scripts publicly available in the coming weeks. For my attempt (48 drives), the amount of data typically backed up each month is approximately 15TB, which takes around 1.5 days to write to multiple LTO-5 tapes in the tape library.
Calculating Pi: My attempt at breaking the Pi World Record
Before I go into the specifics of my record attempt, it is important for you to have some background information. Over the past few years I have been steadily acquiring server hardware to increase my knowledge of system administration and cyber security. This is not only for personal growth: it has also helped me immensely in my professional career. I have served in various roles including cyber security (Cyber Defense Analyst, Chief Information Security Officer) and system administration (Senior System Administrator). Historically, I have also donated my spare system computing resources to various distributed computing projects through the BOINC1 platform. In late 2018 I decided to shift the primary focus of my lab to distributed computing. I still maintain a small 1U server for personal use, but most of the other servers run BOINC exclusively.
UPDATE: Partway through the world record attempt (July, 2019), I founded a nonprofit organization, North Alabama Charitable Computing, which repurposes enterprise-grade compute and storage equipment for STEM research. After I break the Pi world record, most of my servers will be donated where they will provide scientists and various research projects with computing power.
Anyways, back to the reason you are here: My primary reason for attempting to break the record set by Emma Haruka Iwao/Google2 (March, 2019 – 31.4 trillion digits) is to test the limits of my hardware. Once I am finished breaking the Pi world record, the server and hard drives will be repurposed for STEM research (e.g., BOINC, Open Science Grid3, university research projects).
One of the first things I did was reach out to Alexander Yee, who wrote and maintains a program called y-cruncher4. y-cruncher is a program that computes various mathematical constants based on user input. y-cruncher is able to take advantage of the newest processor features and features many optimizations, which in part explains why it has been used to set several of the past Pi records (and other mathematical constants). After emailing back and forth with Alex, I started to gain an understanding of what would be required for such a feat: 50 trillion digits of Pi. In order to calculate this many digits, y-cruncher determined I would need 256TiB of ephemeral storage, in addition to 38TiB for the final output.
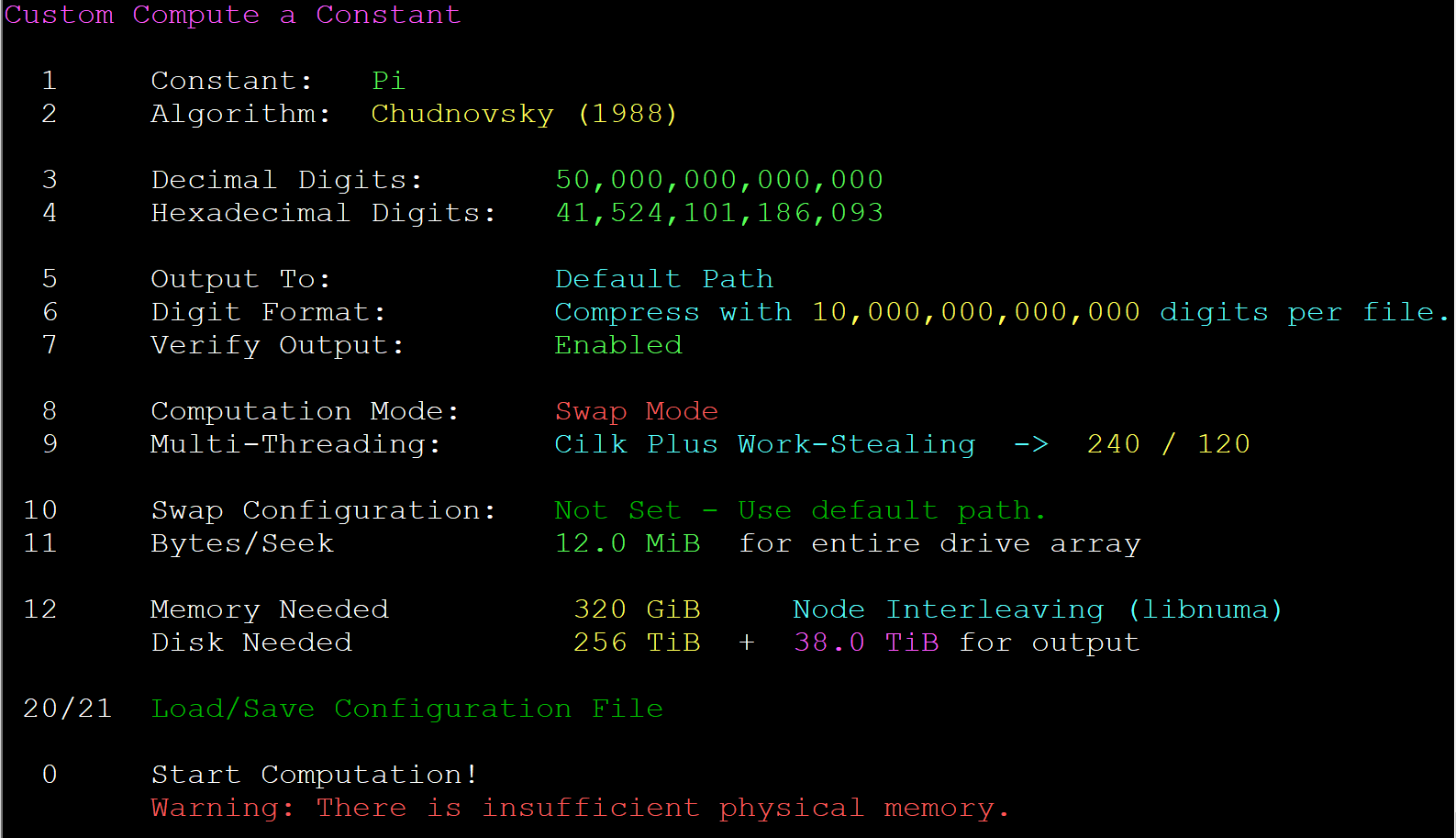
One of the first things that you may notice is that y-cruncher calculates everything in tebibytes (base-2), rather than terabytes (base-10). It can be confusing since these units of measure are sometimes used interchangeably (I’m looking at you, Windows5, and Linux6 df “-h” vs “-H”), but the difference can be significant: for example, 256TiB is equivalent to 281TB. You don’t want to get 3/4 of the way through a record attempt and realize you don’t have enough storage.
Once I had a rough estimate of the amount of equipment and disk required for the Pi computation, I started looking for used hardware, primarily on eBay. From January to March of 2019, I started purchasing equipment that would be required for the attempt: a new server, several hard drives, various PCI-E cards, and a tape libary and drive, to name just a few. Below is a picture of my home lab in it’s entirety (except for an Asus ESC8000 G4 in my office). Everything inside the red box is used for the Pi computation.

- HP PROLIANT DL580 Gen8
- This server (Ubuntu 18.10) performs the Pi computation. The final compressed Pi digits will be transferred to the Dell R720xd via a cifs-mounted directory (/drives/main_output).
- (4) Intel Xeon E7-4880V2 2.5GHz 15C/30T CPU
- 320GB DDR3 PC3-8500R ECC RAM
- (5) 2.5” 100GB SATA MLC SSD (RAID 6)
- (4) 6Gb LSI 9207-8e Dual Port SAS HBA
- Connected to each HPE D3600 disk shelf via single SFF-8088 to SFF-8644 cable 2m
- Intel 10-Gigabit X540-AT2 Dual Port Ethernet Adapter
- Dedicated link to Dell R720xd for Veeam backups
- Intel 1-Gigabit I340-T4 Quad Port Ethernet Adapter
- Connection to the Internet
- (4) HP StorageWorks D3600
- These drives are used to perform computations in lieu of server memory (known as y-cruncher Swap Mode7) to provide the resources required to calculate Pi (mounted on the DL580 as /drives/1 - /drives/48). I originally used HP StorageWorks D2600 disk shelves, but I didn’t realize the SATA backplane was limited to 3Gb/s. I upgraded to the D3600 disk shelf which supports 6Gb/s SATA in June of 2019.
- (12) 3.5” 6TB SATA 7.2K HGST Ultrastar He8 HDD (JBOD)
- Dell PowerEdge R720xd
- This server (Windows Server 2016) serves two primary purposes. First, it is connected to the HP tape library. A Veeam job is manually run each month, which backs up data from the 48 drives running the Pi computation directly to tape. Second, it has an additional RAID6 storage volume (see Dell PowerVault MD1200) which will contain the 50 trillion compressed Pi digits.
- (2) Intel Xeon E5-2670 8C/16T CPU
- 128GB DDR3 ECC RAM
- (2) 2.5” 600GB SAS 10K Seagate HDD (RAID1)
- Emulex LPE 12002, Dual Port 8Gb Fiber Channel HBA
- Connected to tape library using (2) LC-LC OM3 2m fiber cables
- Dell PERC H810 Adapter 6Gb RAID Controller Card
- Connected to Dell MD1200 disk shelf
- Dell PowerVault MD1200
- These drives will contain the compressed Pi digits that y-cruncher generates at the end of the computation.
- 40TB (RAID6)
- (7) 3.5” 4TB 7.2K SAS HGST Hitachi
- (5) 3.5” 4TB 7.2K SAS Seagate Constellation ES.3
- HPE StoreEver MSL4048 Tape Library
- This tape library will contain monthly backups of the forty-eight computation drives.
- LTO-5 FC Tape Drive
- (47) LTO Ultrium 5 Tape Data Cartridge 1.5TB
Here is a timeline of my world record attempt:
- Feb 12, 2019 - This is the day I first reached out to Alex Yee about his y-cruncher program. I told him I was interested in breaking the world record (at that time it was 22.4 trillion digits set by Peter Trueb8). My initial thoughts were to use a NetApp DS4486, NetApp FAS3220 filer, and Dell R910 to compute the record. At this point I wasn’t sure how many digits I was going to calculate, but I knew it was going to be at least 22.4 trillion in order to beat the record (at that time it was the record).
- Feb 12, 2019 - Alex responds with answers to some questions that I had relating to accessing storage and server CPU/memory. I was planning to access the required disk storage using iSCSI on the FAS3220, but Alex pointed out that this would be much too slow even over a 10 Gigabit link. Based on his analysis, I decided to directly connect the storage to the server using SAS cables (SFF-8088). Details were sketchy if I could directly attach the NetApp DS4486 to the main server, or if I would have to use a NetApp filer. After conducting some research, I decided it would just be easier to use external disk enclosures. At the time I was looking at using several Dell PowerVault MD1200 enclosures.
- Feb 13, 2019 - I start looking at the HP Proliant DL580 Gen8 instead of the Dell PowerEdge R910, due to the fact it has a newer processor and higher core count (15/30T vs 10/20T). After some analysis and research, I decide to aim for 50 trillion digits of Pi. I originally planned on using RAID with the hard drives required during the calculation, but the sheer amount of storage required prevented this. In order to mitigate the risk of a hard drive failure, I decided to utilize a HP MSL4048 tape library, which holds a maximum of 48 tapes. The unit I purchased off of eBay just happened to come with 21 LTO-5 tapes (not mentioned in the auction), so that was an added bonus! I got around to purchasing a single full-height LTO-5 tape drive so that I would be able to backup the hard drives to tape. Around the time I was looking for tape backup solutions, Veeam was restructuring their licensing, and the community edition now supported tape backups for up to five hosts. Based on this information, I decide to download Veeam Backup & Replication 9.5 Community Edition and put it on another server (Dell R720xd) connected to the tape library over fiber. After coming to the decision to calculate 50 trillion digits, I determined I would need around 281TB of storage, and after looking on eBay I decided to purchase four HP D2600 external disk enclosures and 48 6TB SATA drives (JBOD) to meet this need. I also saw that I would need 44TB for the final compressed Pi output. I picked up a Dell MD1200 external disk enclosure and 12 4TB SAS drives (RAID6) that would serve this purpose.
- March 14, 2019 - I finally receive all of the hardware necessary for the computation to start. I contact Alex and he recommends I run several tests (I/O performance analysis, swap multiply). I learn that Google has beaten the current world record and was suprised to find that they were interested in this type of computation. Nevertheless, I was still aiming for 50 trillion digits, 18.6 trillion more digits then they computed. I also saw that it cost them around $200,0009, which is very expensive. I’m aiming to stay below 5% of that overall amount.
- Apr 1, 2019 - All of the testing is completed and the I/O seek values are adjusted to 12Mb/s based on the results (due to 3Gb SATA backplane on HP D2600). I start the world record computation.
- April 2, 2019 - y-cruncher Status update: Series: S ( 17 ) 1.419%
- Apr 3, 2019 - I log into the server and I am greeted with the following error message: “A Raid-File operation has failed.” After reaching out and troubleshooting, Alex recommends adjusting the ulimit value on Linux (by default, Linux only allows you to have 1023 open files handles by default)10. I set the ulimit value to a very high value in order to prevent this issue from happening again, and this fixes the issue.
- April 4, 2019 - y-cruncher Status update: Series: S ( 16 ) 1.794%
- April 4, 2019 - y-cruncher Status update: Series: S ( 15 ) 2.268%
- April 5, 2019 - y-cruncher Status update: Series: S ( 14 ) 2.867%
- April 6, 2019 - y-cruncher Status update: Series: S ( 13 ) 3.625%
- April 8, 2019 - y-cruncher Status update: Series: S ( 12 ) 4.584%
- April 10, 2019 - y-cruncher Status update: Series: S ( 11 ) 5.796%
- April 13, 2019 - y-cruncher Status update: Series: S ( 10 ) 7.330%
- April 16, 2019 - y-cruncher Status update: Series: S ( 9 ) 9.271%
- April 21, 2019 - y-cruncher Status update: Series: S ( 8 ) 11.727%
- April 27, 2019 - y-cruncher Status update: Series: S ( 7 ) 14.836%
- May 6, 2019 - y-cruncher Status update: Series: S ( 6 ) 18.773%
- May 16, 2019 - y-cruncher Status update: Series: S ( 5 ) 23.761%
- May 31, 2019 - y-cruncher Status update: Series: S ( 4 ) 30.086%
- June 15, 2019 - I email Alex asking if there would be any issue upgrading my 3Gb/s SATA D2600 external disk enclosures to the D3600 6Gb/s model. He says there won’t be any issue as long as the drives and mount points appear the same to the operating system.
- June 19, 2019 - y-cruncher Status update: Series: S ( 3 ) 38.116%
- June 23, 2019 - I swapped out the D2600 disk enclosures with the D3600 model. I transfer all forty-eight drives to the new enclosures. I had to purchase new drive caddies as well (HP Gen8 model caddy vs Gen5/6 caddy), since the new enclosure drive bays are less wide than the older model. I let Alex know the disk enclosure transfer appears to have been successful and share the updated drive speed metrics – write speed: 3.15 GiB/s (old) vs 5.69 GiB/s (new), read speed: 3.08 GiB/s (old) vs 5.90 GiB/s (new). Based on the increased (nearly doubled speed), Alex lets me know the computation should finish a month or two ahead of schedule.
- July 14, 2019 - y-cruncher Status update: Series: S ( 2 ) 48.327%
- August 15, 2019 - y-cruncher Status update: Series: S ( 1 ) 61.346%
- September 21, 2019 - y-cruncher Status update: Series: S ( 0 ) 78.042%
- November 9, 2019 - y-cruncher Status update: Finishing Series
- November 14, 2019 - y-cruncher Status update: Large Division
- November 26, 2019 - y-cruncher Status update: InvSqrt(10005)
- December 25, 2019 - y-cruncher is in the middle of performing the output base conversion (after writing the hexadecimal digits). Due to severe weather, I had to shut down the server. This was unfortunate because the program is unable to checkpoint during the base conversion process, meaning I lost about 2 weeks worth of work.
- December 31, 2019 - As luck would have it, a transformer next to my house blew and the power went out yet again. This means I had to restart from the last checkpoint yet again, losing another 2 weeks worth of work.
- January 18, 2020 - Base conversion finished. y-cruncher begins writing the Pi decimal digits.
- January 20. Decimal digits written. Begin verification of base conversion, decimal output, and hexadecimal output.
- January 29, 2020 - Pi Computation is finished! The world record appears to be broken!
-
https://cloud.google.com/blog/products/compute/calculating-31-4-trillion-digits-of-archimedes-constant-on-google-cloud ⤴
-
https://blog.livedrive.com/2012/08/why-a-windows-terabyte-isnt-really-a-terabyte/ ⤴
-
http://www.numberworld.org/y-cruncher/guides/swapmode.html#intro ⤴
-
http://www.numberworld.org/y-cruncher/news/2016.html#2016_11_15 ⤴
-
https://easyengine.io/tutorials/linux/increase-open-files-limit/ ⤴